今天这篇推送是本公众号的第666篇原创内容,前几天我们的订阅读者数目也超过了16666,我们当然希望能够越来越6,这离不开大家的支持,请各位多多给我们点赞哦哈哈哈!
先回顾一下我们上一个公众号(上海交大软件安全研究组GoSSIP)在2020年自然灾害刚刚爆发的时候的论文推荐【G.O.S.S.I.P 学术论文推荐 2020-04-23】(当时是由热心群友Vancir推荐的),介绍了一个名为BinRec的框架,实现了二进制代码重编译——也就是先反编译,然后再编译成机器代码(可能是和原来不一样的ISA)——的功能:
https://github.com/trailofbits/binrec-tob
在当时我们曾经介绍过,BinRec的特点是借助各类输入(包括具体的输入、半符号化输入和纯符号化输入)来辅助进行动态分析,然后通过程序执行记录(tracing)来帮助后续的二进制代码转换。时隔4年,当时的部分论文作者(当时是来自UC Irvine和VU Amsterdam还有KU Leuven的作者合作)再接再厉,在ASPLOS 2024上发表新的研究论文What You Trace is What You Get: Dynamic Stack-Layout Recovery for Binary Recompilation,为BinRec带来了升级,具体升级了什么特性,且看下文分解。

我们在【G.O.S.S.I.P 阅读推荐 2022-08-08 Demystifying Binary Lifters】里面曾经介绍过,在IEEE S&P 2022的研究论文中,研究人员对binary code lifter的缺点进行了系统性总结,其中也评测了BinRec,并且还专门指出代码优化和局部变量识别这两点是lifter可以改进的方向。于是在今天的这篇论文中,作者进行了回应,对二进制代码重编译工作中的局部变量(local variable)识别工作进行了改进,设计了WYTIWYG工具(What You Trace is What You Get的缩写)实现对BinRec的升级。
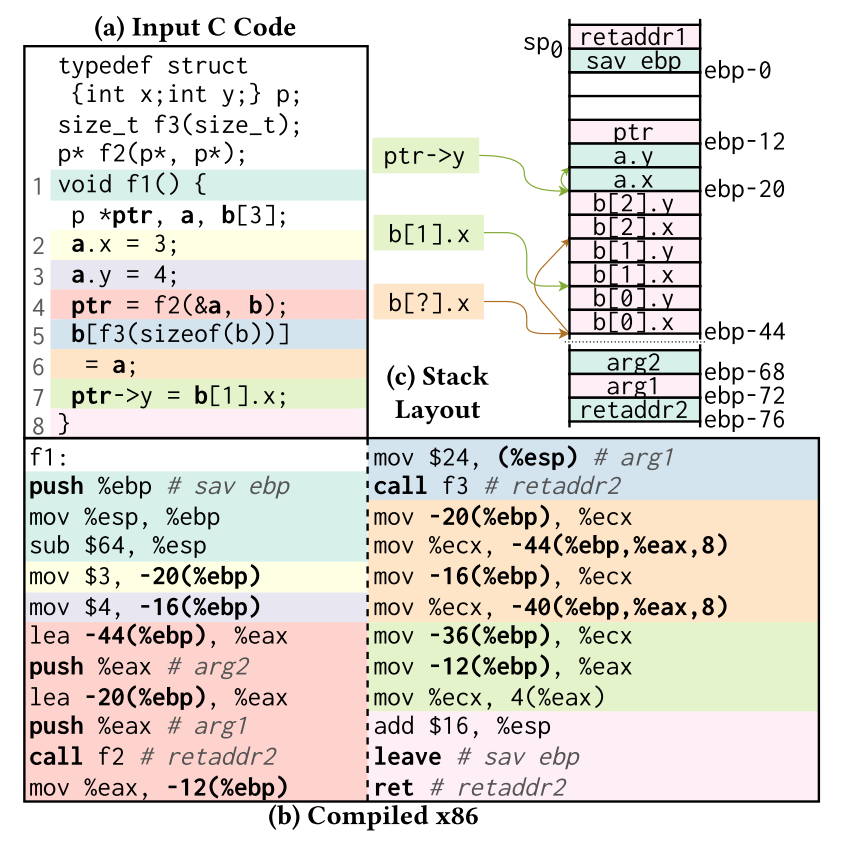
作者首先举了一个非常复杂的例子(下图)。主要想要表达的意思就是说,反编译器可能最终只能把stack上的不同的局部变量识别为同一类——也就是说,都基于栈指针(stack pointer,SP)加上或者减去特定偏移的表示方法。虽然我们看IDA的输出时已经习惯了这种style,但是如果能更为智能地进行识别,那岂不是更好?
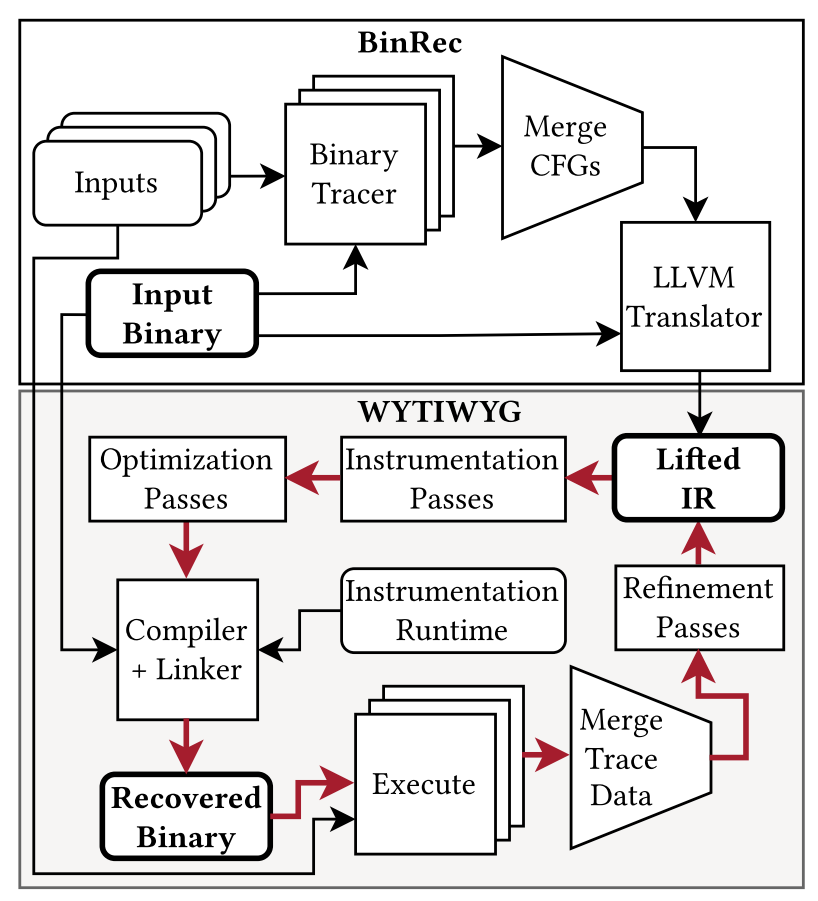
WYTIWYG在BinRec的基础(动态二进制指令追踪记录功能和二进制代码翻译到LLVM IR功能)之上,增加了一套叫做refinement lifting(这听上去有点去蹭人家AI热点的嫌疑)的方法,下图展示的就是WYTIWYG的工作流程,不过看上去太抽象了,似乎什么都没说明白,我们继续看细节。
论文的第四章是WYTIWYG的核心,主要讨论了三方面的问题。第一,尽管我们直觉上认为在机器指令里面访问局部变量就是“栈指针加偏移”的方式,但是编译器优化也会用一些寄存器来保存特定变量的指针,这种情况必须要用动态追踪的方式来精确识别,从而标记出所有对stack上的数据进行访问的操作(论文4.1章);第二,在标记出访问stack的操作后,利用内存访问的特点,对stack frame(也就是一个函数会拥有的一整块stack空间)进行切分,从而把stack frame划分成属于不同变量的区域(论文4.2章),而在这里就需要考虑非常多的因素,既需要使用动态追踪(下图)去记录各种对stack的访问(目的是去找到不同的stack变量对应的base pointer),同时要计算出基于同一个base pointer访问的范围(最大偏移和最小偏移),最后根据这些记录来进行stack frame的划分。
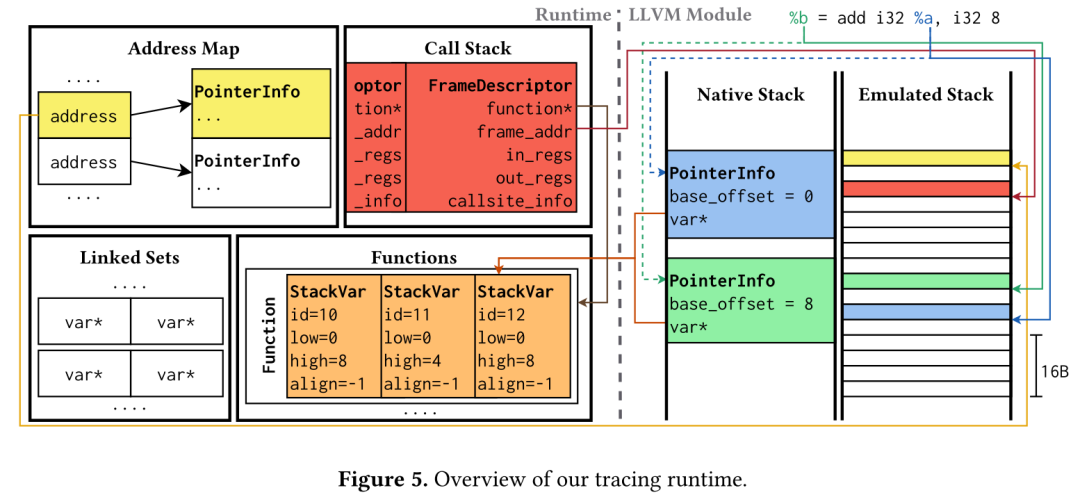
第三,在整个分析过程中,需要考虑诸多因素,包括编译器优化导致的“指针越界”访问(例如下图中这种数组访问优化,最后会产生一个negative的偏移,记得好像是在体系结构的教材上也介绍过?),还有函数传参的一些特点,这部分细节都可以在论文的4.2章中找到。

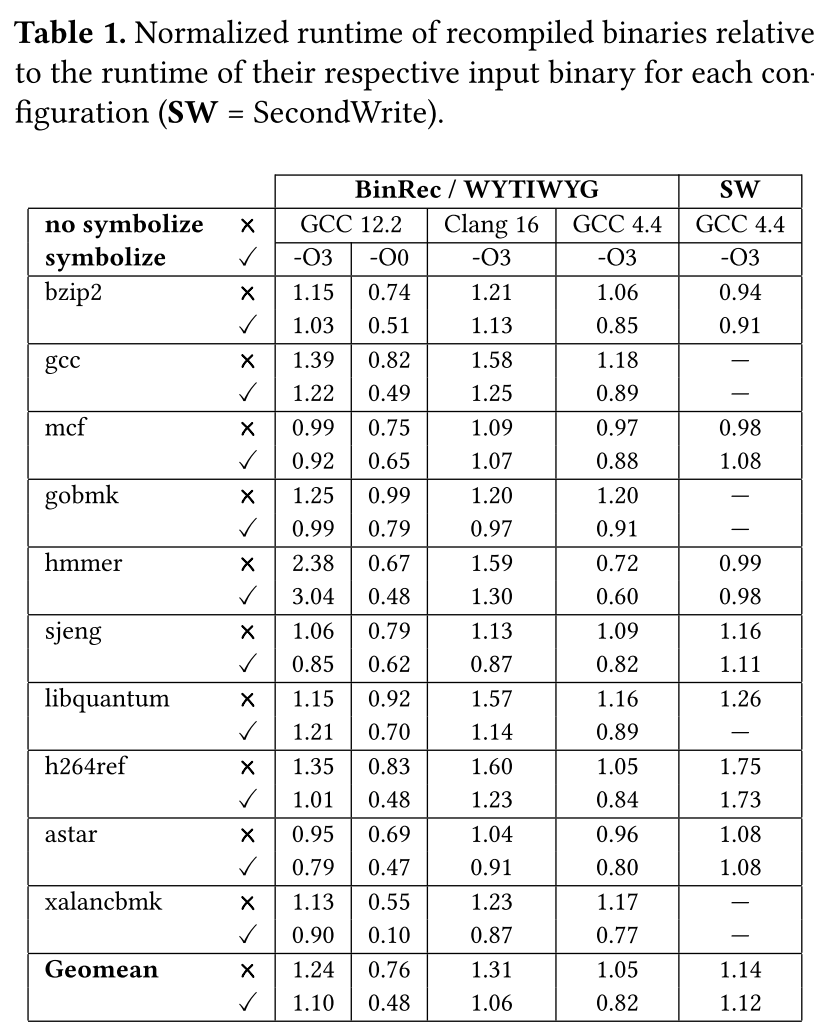
讲完了方法,让我们看看实验,作者使用了SPECint 2006 benchmark suite进行测试,将WYTIWYG和另一个二进制代码重写工具SecondWrite进行了对比,首先作者用了GCC 12和Clang 16来进行编译,还开启了编译优化(O3),WYTIWYG可以很好处理所有编译选项生成的二进制代码,反编译和重编译都没问题,而SecondWrite只能处理GCC 4.4生成的二进制代码(据说百度内部还是用的这个版本的GCC,呸呸呸不传谣不信谣)。然后测试了重编译代码的性能损失(下表),可以看到WYTIWYG相比于BinRec(更加精确的stack variable标记)能够有效提升重编译代码的运行性能(每一项的数字越小,表示性能提升越大),而即使编译器开启了O3优化,WYTIWYG最多也就引入了10%的性能开销(GCC -O3,1.10)。
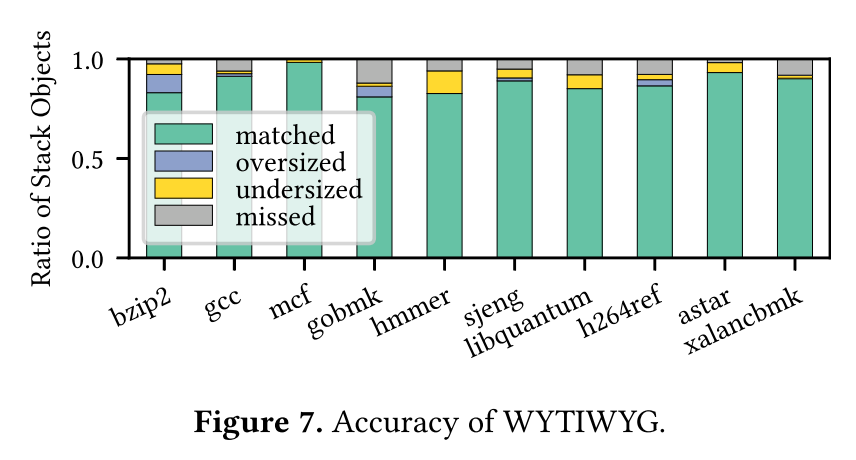
最后,作者用LLVM 16的Stack Frame Layout analysis功能来生成ground truth,然后与之对比,WYTIWYG 准确度,在没有额外数据辅助的情况下,WYTIWYG实现了94.4%的precision和87.6%的recall,看起来相当不错哦!
当然,2020年的BinRec代码开源让大家等了很长时间,今年的WYTIWYG更是提都没提开源的事情了,希望作者能够尽早把工具开放出来造福我们!
论文:https://dl.acm.org/doi/abs/10.1145/3620665.3640371