今天为大家推荐的论文来自浙江大学投稿的发表在ISSTA 2024上的最新工作Atlas: Automating Cross-Language Fuzzing on Android Closed-Source Libraries。浙江大学常瑞老师研究组自研的Atlas主要解决针对安卓平台闭源第三方库的自动化模糊测试问题,在多个移动安全平台上首次发现并披露了高危的远程代码执行工作,作为唯一高校入选者当选2022 年三星移动安全名人堂Top10,同时相关研究内容受邀在国际安全会议 Zer0Con2023 上进行了议题演讲。

背景与挑战
在安卓应用层中,为了提升效率,使用了大量第三方 native 库来完成图像解析、音频解析等复杂功能。这些库往往由 C/C++ 语言实现,因此容易受到内存破坏型漏洞的影响。一旦其中出现了可利用的内存破坏型漏洞,攻击者可以通过远程发送文件等方式来完成高权限进程中的远程代码执行攻击,进而实现窃取隐私数据等目的。
模糊测试是近年来流行的自动化挖掘漏洞的方式之一,被广泛应用于软件到系统层面的自动化漏洞挖掘中。为了对安卓闭源第三方库进行模糊测试,需要人工构建一个可用的模糊测试驱动(Fuzz Harness)。这个过程是繁琐而复杂的,首先需要人工逆向分析,从应用层中发掘对闭源库的使用方法,尤其是函数调用顺序以及参数设置。其次,这涉及到了跨语言编程模型(应用层由Java代码实现,而闭源库由C/C++代码实现)。如何成功运行Harness是一个需要解决的问题。在现有的模糊测试研究工作中,显然缺乏了针对安卓闭源第三方库的跨语言运行时环境,并且现有闭源二进制库的自动化模糊测试工作均针对单语言闭源程序,难以应用到跨语言编程模型的安卓闭源第三方库中。因此,对于闭源安卓第三方库的模糊测试主要存在以下两个挑战:
挑战一:安卓第三方库中普遍存在跨语言编程模型且无法获得源码。目前针对闭源库自动化生成模糊测试驱动的工作(例如 APICraft、WINNIE)主要通过动态执行的方式收集接口的依赖以及参数信息,后续基于此进行模糊测试驱动的生成。然而在测试安卓应用第三方库的场景中,动态触发的方式会因为被测接口数量庞大,产生很大的时间开销。同时,这种方式可能会因为触发方式或者样本数量不够全面而产生遗漏。除此之外,这样的方式无法结合分析来自跨语言上下文的信息来生成有效的模糊测试驱动。
挑战二:安卓闭源第三方库的跨语言运行时环境复杂。目前针对安卓闭源第三方库的模糊测试框架难以在提供完备模糊测试环境的同时,保证模糊测试的效率。一方面,现有的研究工作都在真实设备或者单语言运行时环境中执行模糊测试驱动。而真实设备成本高且 CPU 算力有限。另一方面,现有单语言的模糊测试运行时环境给包含跨语言编程模型的闭源第三方库的驱动编程带来了很多不便。现有的研究通过直接调用下层接口,避开 JNI 调用,从而实现在单语言的运行环境中模糊测试。这种方式需要大量人工逆向的工作将原有跨语言的程序重写为单语言的驱动程序,因此容易出错且效率低,不利于大规模的自动化模糊测试。
框架设计
为了解决以上的挑战,本文设计了一个针对安卓闭源第三方库的自动化模糊测试框架 Atlas ,如下图所示:
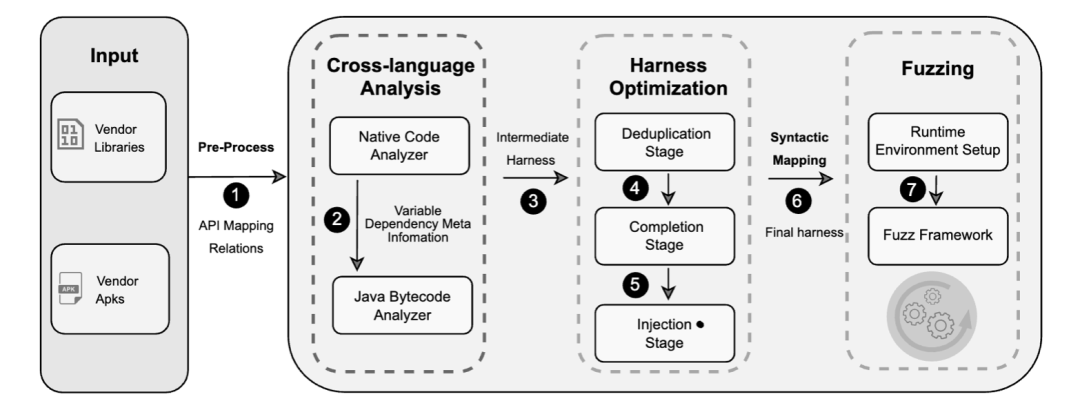
Atlas 将闭源第三方库以及调用其中接口的应用作为输入,主要包含两个组件,一是自动化驱动生成组件,包括跨语言的静态分析器以及驱动优化器,另一个则是包含跨语言执行环境的模糊测试引擎。
跨语言静态分析:在 native 层对 JNI 函数进行建模,通过符号执行以及污点分析来获得目标接口对于 Java 变量的读写情况,用以推断 API 之间的潜在依赖。Java 分析器接收来自 native 层的接口信息,基于对 Java 目标接口所在的 CFG 进行分析,对字节码进行自底向上的多路径切片分析,保留与调用目标接口相关的字节码,输出中间态驱动。
自动化驱动优化:输出的中间态驱动会存在重复率高、参数或者调用序列不完整,这些是静态分析本身的缺陷所造成问题。除此之外,大量的驱动需要判定是否可以进行模糊测试。于是提出了三个自动化驱动优化阶段来提高其质量:去重阶段通过聚类分析来保留独立驱动;完善阶段通过启发式插入来补全参数以及调用序列;注入阶段通过参数语义来判定是否可以被测试并传入模糊测试数据。
跨语言运行时环境构建:为了解决现有用户态模拟器中缺乏 Java 运行时环境的问题,本文将 JVM 移植到现有的用户态模拟器环境中,再通过自动化递归识别 native 层以及 Java 层的依赖项来解决闭源第三方库的复杂依赖问题。这一运行时环境不仅轻量可拓展,而且提供了可标准化的驱动构架方式。
实验与结果
本文首先在来自 4 个不同厂商涵盖不同功能的 17 个 app 上测试 Atlas 的通用性。实验结果显示,对其中 767 个 native API 共计生成了 820 个驱动,51% 是可以直接编译运行的,27% 需要少量的人工修复。
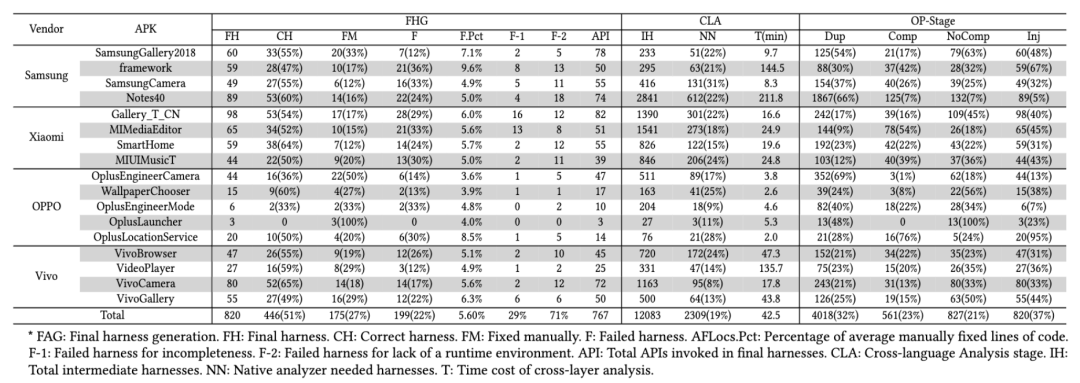
为了验证其生成驱动的质量,在真实应用上进行覆盖率对比实验,发现 Atlas 生成的驱动产生的覆盖率平均达到了人工构建驱动的 1.37 倍。
在生成驱动的过程中,对 Atlas 中的每个组件进行贡献评估。实验结果显示,19% 的驱动生成用到了来自 native 层的信息,平均去重率达到了 68%,23%的驱动被补全 ,37% 的驱动被判定为可注入。
为了评估跨语言模糊测试运行时环境的必要性,进行了人工驱动构建实验。在 Altas 的运行时环境中,驱动构建的成功率达到了 84%,而使用现有的 API 重写的方式时的成功率只有 56 %。
为了评估模糊测试的效率,本文选取了 8 个开源程序,并使用 JNI 编程的方式调用其中接口,在不同的软硬件平台上进行速吞吐率测试,其结果如下。
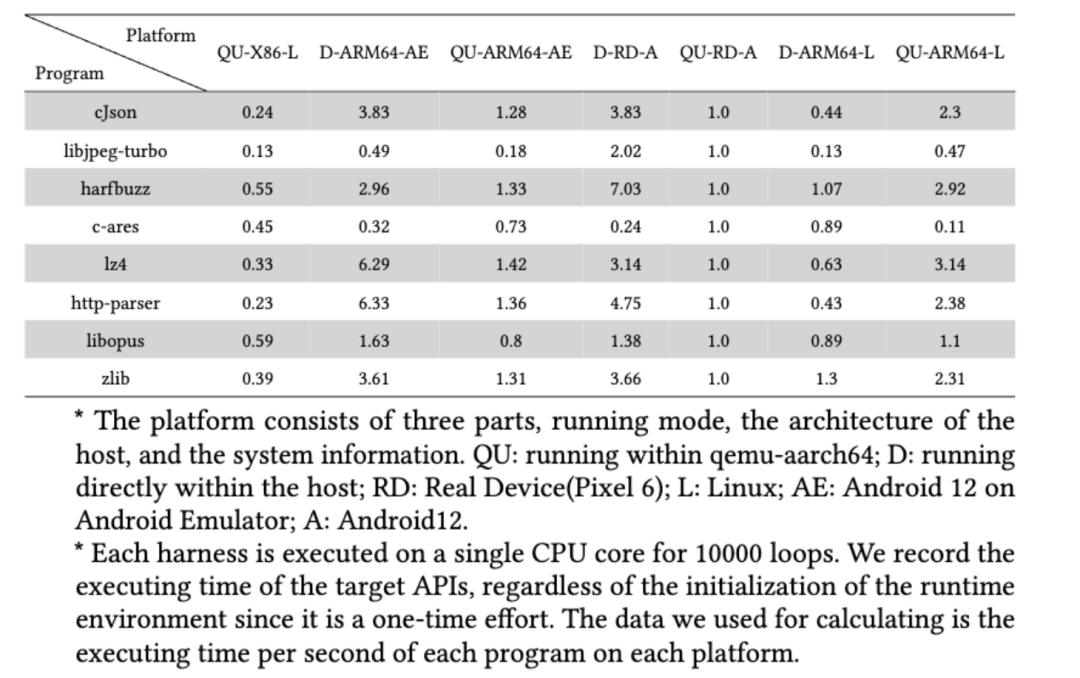
实验结果显示,Atlas 在 X86 平台上的性能平均为真机上的 37.4%,ARM64 平台上的性能平均为 73.3%。
最后本文对 Atlas 的真实漏洞挖掘能力进行了评估,在不同厂商的 13 个预置应用中发现了 74 个安全类型的 bug,获得了 16 个 CVE。
对Atlas工作感兴趣的朋友可以直接联系文章作者呀~
投稿作者介绍
熊皓、戴勤明:本文的共一作者,均为2021 级浙江大学计算机科学与技术学院硕士,导师为常瑞老师。主要研究方向为系统与软件安全。浙江大学AAA 战队成员。多次向三星移动安全平台以及 Linux 内核社区报告漏洞。入选2022 年三星移动安全名人堂。曾在Zer0Con、ISSTA、TSE 、S&P 上发表过相关研究成果。