大家好,今天给大家推荐一篇发表于NDSS 2024关于机器学习模型训练数据盗用检测的研究工作-ORL-AUDITOR: Dataset Auditing in Offline Deep Reinforcement Learning,由浙江大学控制科学与工程学院NeSC课题组与浙江大学计算机科学与技术学院DAILY、NESA课题组共同完成并投稿。

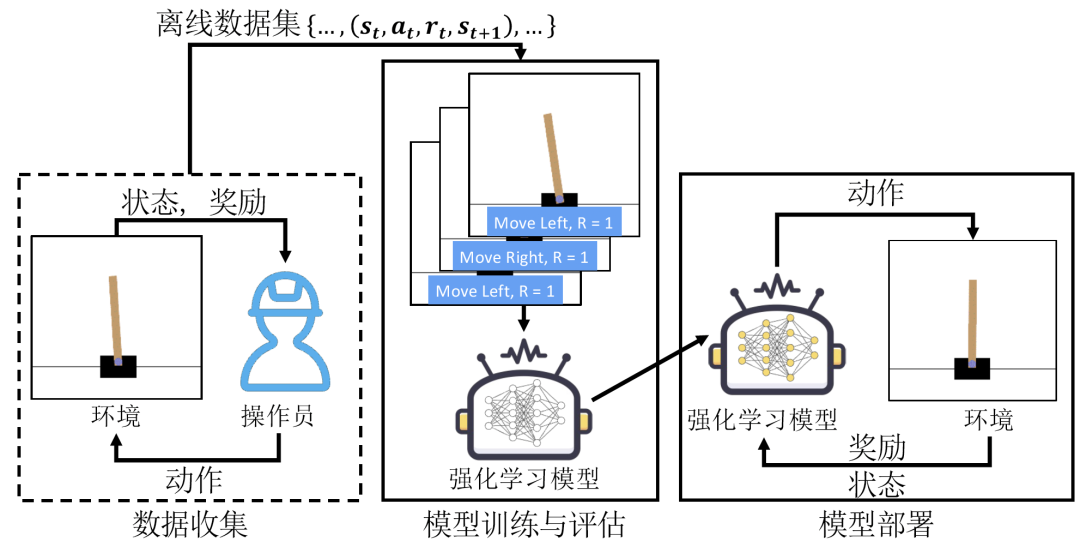
深度强化学习已广泛应用于诸多现实生产场景,例如电力调度、自动驾驶等领域。在实际场景中,在线强化学习(Online RL)直接与物理环境进行交互并实时调整策略可能会带来严重的安全隐患。为此,研究者提出离线强化学习(Offline RL),允许模型在预先收集好的数据上进行训练以降低安全风险。高质量的训练数据能够保证模型的性能和泛化能力,已成为数据所有者的关键资产。
本文提出了无需水印的细粒度强化学习训练数据集盗用检测方法。方法的核心思想是训练数据集的奖励信息可以作为数据集内生指纹,用于判定嫌疑模型在训练过程中是否使用了目标数据集。为了验证所提方法的有效性,本文在4种经典离线强化学习方法和3个常用的强化学习任务测试所提方法的检测性能,所提方法在误报率低于2.88%的情况下达到95%以上的检测准确率。鲁棒性测试结果表明所提方法可以抵抗模型集成和模型输出扰动等对抗攻击,所提方法在干扰情况下依旧可以取得80%以上的检测准确率。最后,本文将所提方法应用于 Google 和 DeepMind 开源数据集的盗用检测,所有检测准确性均高于95%。
预备知识
离线强化学习
模型需要基于预设数据集
问题建模
应用场景
下图展示了一个典型的应用场景,数据所有者在形成标准数据集后将其发布或销售给客户。拥有数据集访问权限的恶意客户(攻击者)会进行盗版分发或非法构建模型即服务平台(MaaS)。机构1怀疑这些模型在训练过程中使用了其数据集
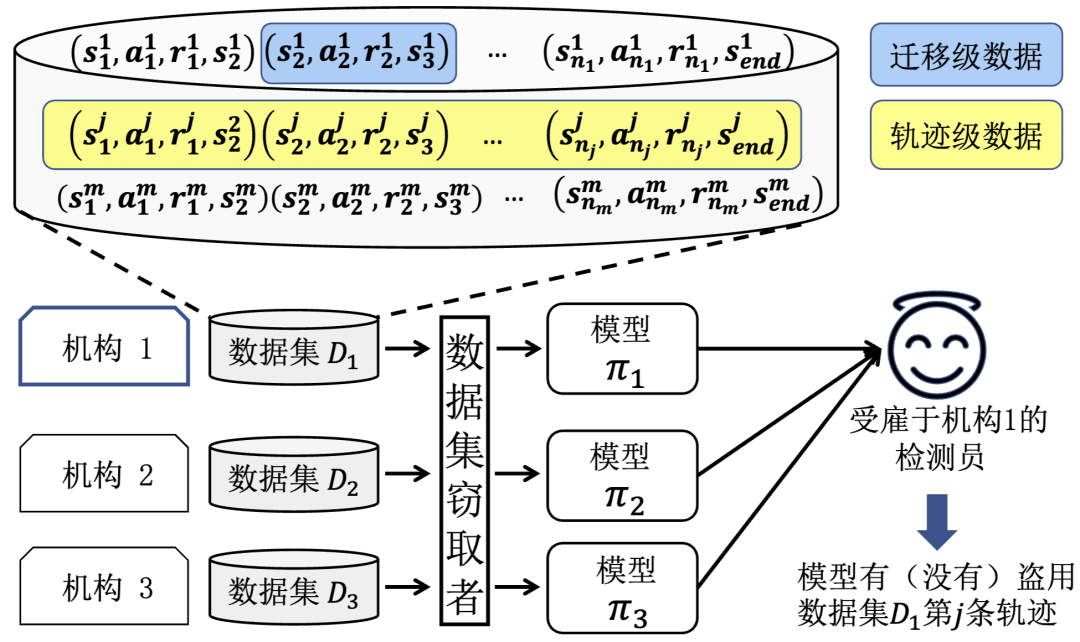
检测员能力假设
检测员掌握目标数据集的所有信息,例如数据集中轨迹数量、状态和动作的取值范围。
在离线强化学习场景中,检测员无法与在线环境交互以收集更多数据,即整个检测过程仅依赖于目标数据集。
检测员对嫌疑模型具有黑盒访问权限,即检测员只能访问嫌疑模型的输入、输出,而不能获取任何模型内部的信息。
设计思路
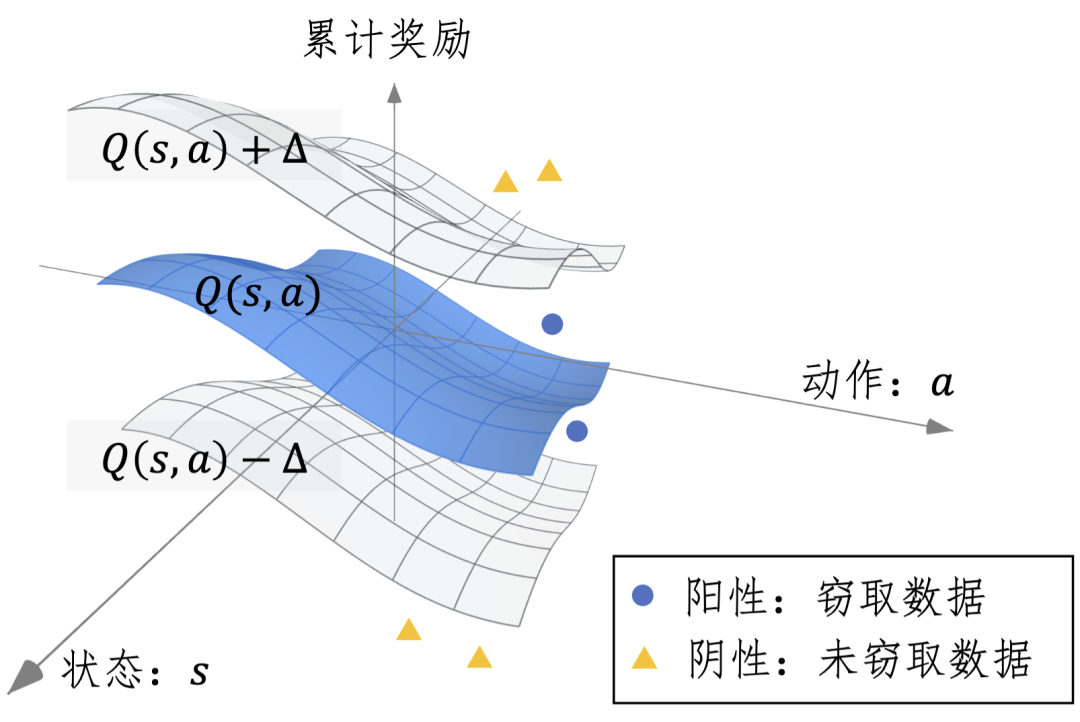
本文发现累计奖励——从特定的状态-行动对开始在一段时间内收到的所有奖励信号之和——塑造模型的行为策略。
因此,累计奖励作为数据集的内在特征使其成为合适的审计依据。上图提供了所提方法的原理示意图,其中状态、动作和累计奖励组成了一个三维空间。中间面表示数据集中状态-动作对的真实累计奖励,而其他两个曲面则展示了检测的决策边界。
累计奖励作为数据集的内在特征满足本文涉及场景的检测要求,所以本文选择使用累计奖励来实例化
。 对于
,本文基于在数据集上训练的影子模型构建决策边界而不是预设的阈值,以适应不同数据集的分布。
对于一个嫌疑模型,如果它的状态-动作对的累计奖励落在两个边界之间,检测员会输出一个阳性结果即嫌疑模型在训练过程中盗用了该数据集。否则,检测员输出一个阴性结果即嫌疑模型在训练过程中没有盗用该数据集。
实验评估
实验设置
强化学习任务
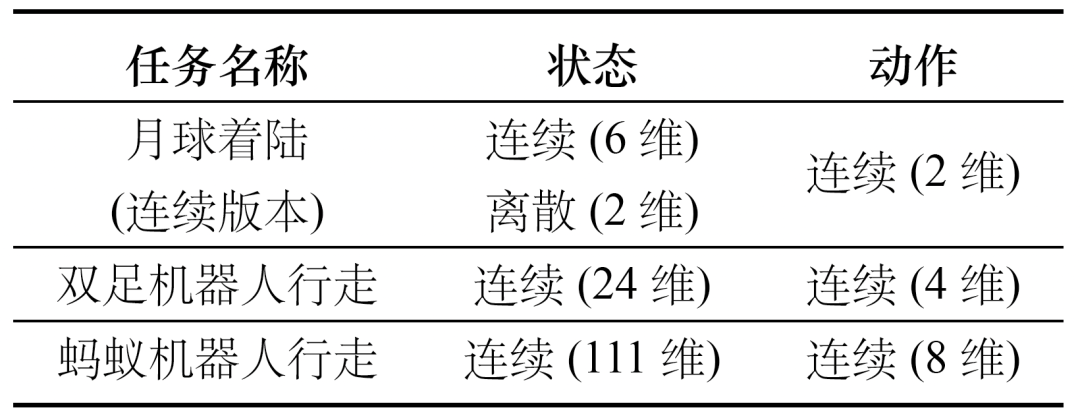
本文采用Gym中的月球着陆(Lunar Lander)、双足机器人行走(Bipedal Walker)和蚂蚁机器人行走(Ant)三个任务。
这些任务在现在研究中被广泛使用,覆盖离散、连续的状态和动作空间,状态和动作空间的维度从低维度(2维)到高维度(111维)。
参数设置
为了便于复现,本文在开源代码的基础上提供了所使用的随机种子。

评估指标
本文同时展示了True Positive Rate和True Negative Rate,以避免Accuracy指标可能受到正负样本比例的影响。
实验结果
总体性能
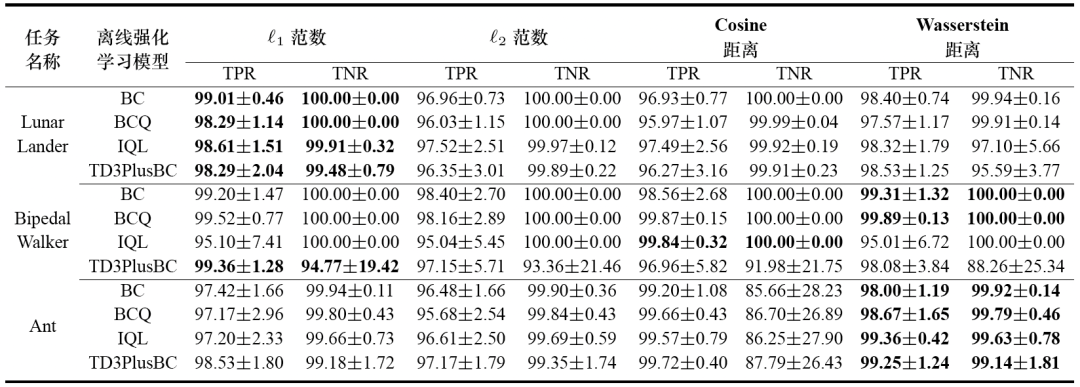
下图中展示了所提算法在三个强化学习任务和四个训练数据集上的检测准确率。实验结果表明:1)绝大多数TPR和TNR都超过95%,证明了所提方法的有效性;2)所提方法在四种距离度量上获得了不同的检测精度。
累计奖励可视化
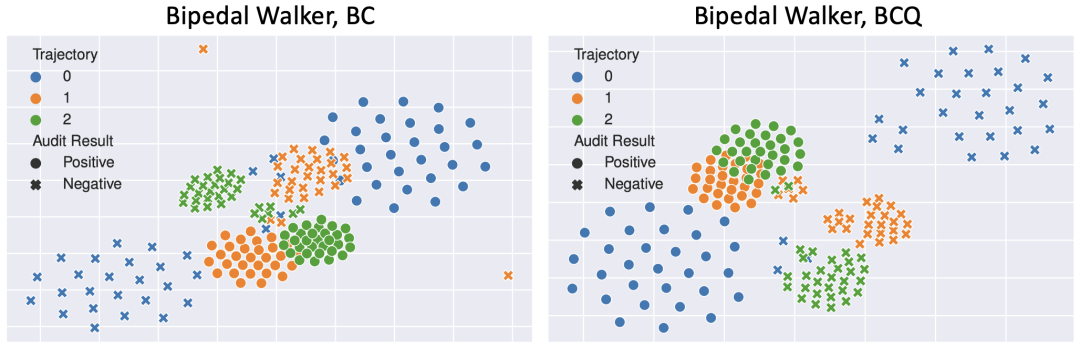
为进一步解释上述检测效果,下图使用t-SNE分别可视化阳性模型和阴性模型的累计奖励。实验结果表明,对于目标数据集中的轨迹,来自影子模型和嫌疑模型的累计奖励明显地被分成两组,证明累计奖励能够很好地反映模型行为之间的差异。因此,由评论家模型生成的累计奖励可以作为轨迹级数据盗用检测的依据。
鲁棒性测试
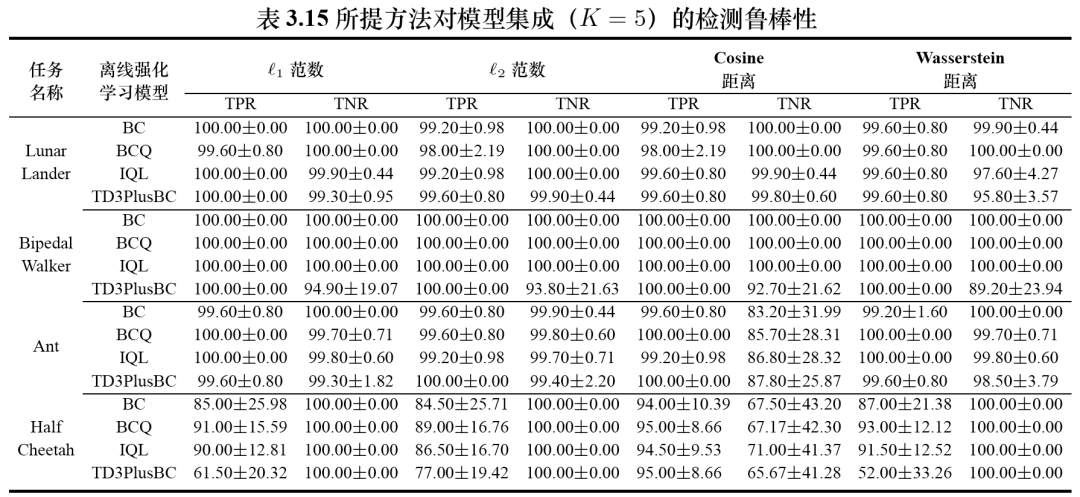
模型集成
模型集成方法将训练数据集分成若干子集,并在每个子集上分别训练子模型。当检测员使用目标数据集中的样本对嫌疑模型进行检测时,数据盗用者会聚合那些未在该样本上进行训练的子模型的输出以躲避检测。下图实验结果表明:1)即使数据盗用者使用了模型集成,所提方法仍然能够保持较高的检测准确率;2)使用模型集成可能会导致在某些任务上模型正常性能下降。
扰动模型输出
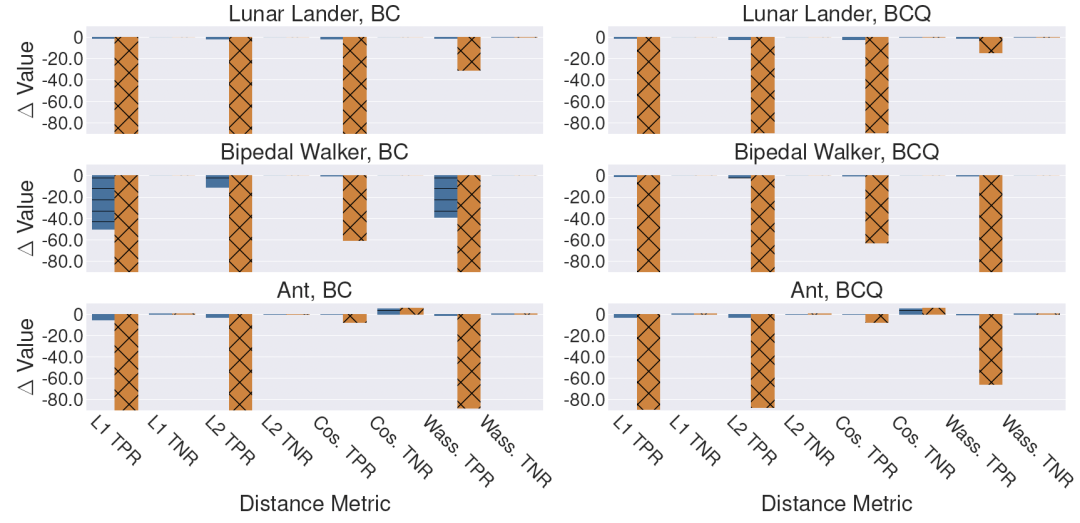
嫌疑模型可以通过扰动输出隐藏其盗用训练数据集的行为。本文分别使用
下图实验结果表明:1)所提方法能够抵抗来自嫌疑模型的输出扰动,尤其所提方法使用余弦距离度量;
2)所提方法在只使用单一距离度量时,对于强扰动的抵抗能力较弱。
论文原文:https://www.ndss-symposium.org/wp-content/uploads/2024-184-paper.pdf
开源代码:https://github.com/link-zju/ORL-Auditor
投稿作者介绍:
杜林康 西安交通大学 助理教授
分别在2018年、2023年获浙江大学学士、博士学位,并在攻读博士学位期间受国家留学基金委的资助前往德国亥姆霍兹信息安全中心(CISPA)Michael Backes主任课题组学术访问一年。目前已发表/录用多篇网络与信息安全四大顶级会议论文。
个人主页:http://cybersec.xjtu.edu.cn/info/1015/1962.htm